ERL-VLM Method
ERL-VLM queries large vision language models (VLMs), such as Gemini and ChatGPT, for rating feedback on individual trajectories in order to learn a reward model. Compared to preference-based feedback, this approach allows VLMs to provide more expressive evaluations, reduces ambiguity in queries, and ensures that all samples are fully utilized during reward learning.
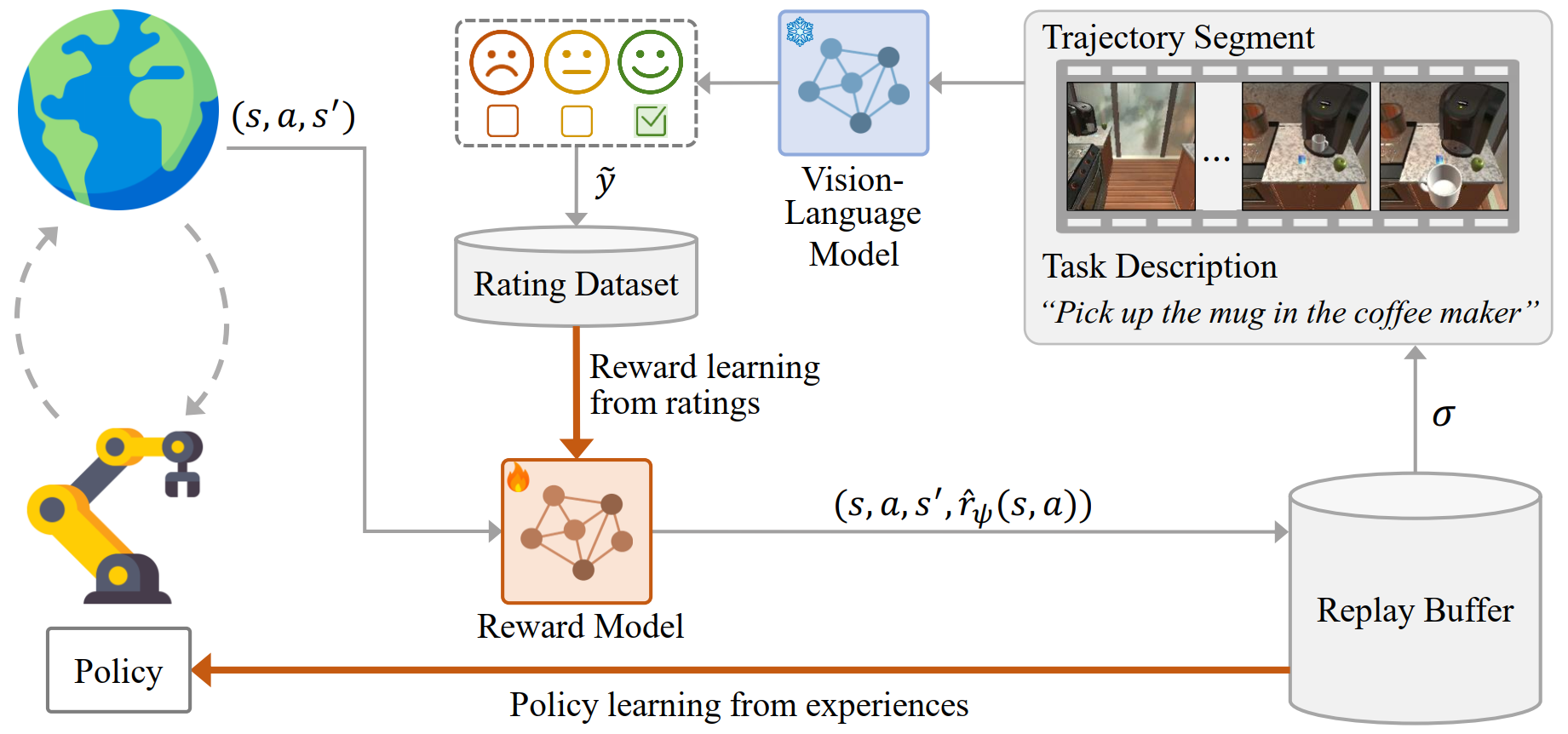
While training the ERL-VLM agent, we sample a state (a single image) or a trajectory (multiple images) from the replay buffer and use it together with a task description to query a large VLM for ratings. The sampled states or trajectories, along with their corresponding ratings, are then stored in the rating dataset. We use rating-based RL to learn the reward model from this dataset, incorporating two improvements: (i) stratified sampling and (ii) mean absolute error loss, to address instability caused by data imbalance and noisy labels from VLMs. The learned reward model is then used to train the agent using off-policy RL algorithms such as SAC or IQL.